Parallelism: hardware doesn't create parallelism
May 27, 2026
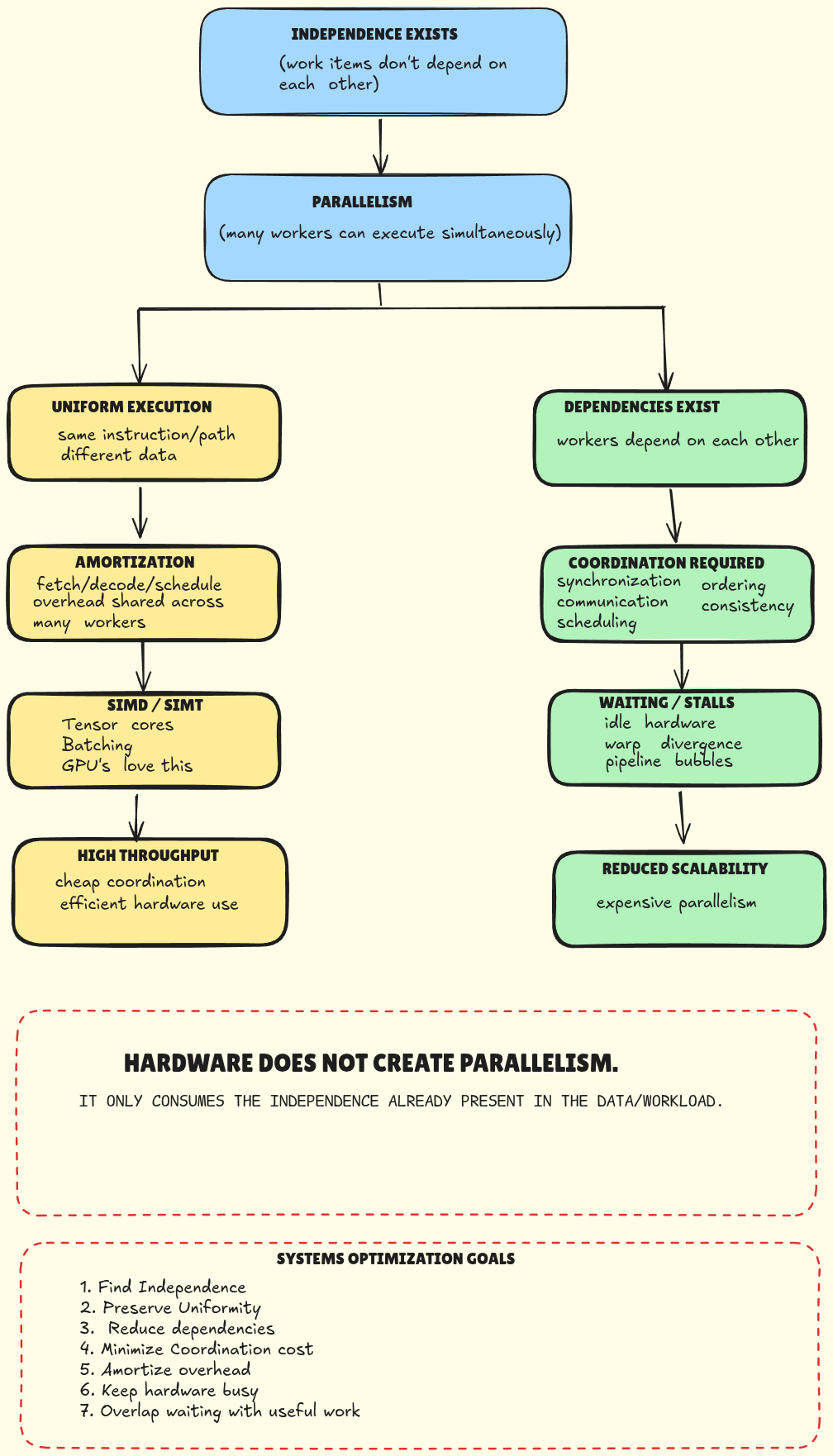
One of the deepest realizations I'm having about systems / GPU / distributed computing:
Hardware does NOT create parallelism.
It only consumes parallelism that already exists in the data / workload.
That changes everything.
Parallelism fundamentally comes from:
- independence
Not from:
- GPUs
- CUDA
- tensor cores
- clusters
Those are merely engines that exploit independence efficiently.
The deepest systems law
Independent work → scales well
Dependent work → coordination cost appears
And coordination creates:
- synchronization
- communication overhead
- scheduling complexity
- ordering constraints
- consistency problems
- stalls
- idle hardware
That's why systems engineering becomes hard.
Amdahl's law makes this concrete. If a fraction $f$ of the work is parallelizable and the rest $(1-f)$ is serial, then with $p$ workers:
$$ S(p) \;=\; \frac{1}{(1-f) \;+\; \dfrac{f}{p}} \quad\xrightarrow{p \to \infty}\quad \frac{1}{1-f} $$
- The serial fraction $(1-f)$, every bit of coordination, dependency, synchronization, sets a hard ceiling on speedup, no matter how many GPUs you throw at the problem.
- Even $1\%$ dependent work caps speedup at $100\times$. That's the cost of dependence, written as a number.
Distributed inference, suddenly clear
Single-GPU inference:
- mostly local computation
- minimal coordination
Distributed inference:
- activation transfers
- all-reduce
- KV synchronization
- pipeline dependencies
Now GPUs become dependent workers. And dependent workers create:
- waiting
- communication
- synchronization
- bottlenecks
Which is why scaling distributed systems is hard.
The communication cost is also a formula. A ring all-reduce of an $m$-element gradient across $p$ GPUs takes roughly
$$ T_{\text{allreduce}}(p, m) \;\approx\; 2(p-1)\,\alpha \;+\; 2\,\frac{p-1}{p}\,\beta\,m $$
- where $\alpha$ is per-message latency and $\beta$ is per-byte time.
- As $p$ grows the latency term $2(p-1)\alpha$ blows up linearly, every extra GPU adds round-trips.
- The data term $\frac{2(p-1)}{p}\beta m \to 2\beta m$ saturates.
- So at scale, latency, not bandwidth, is what kills you and that latency exists only because the workers depend on each other.
Modern hardware LOVES uniformity
Why? Because control overhead is expensive too:
- instruction fetch
- decode
- scheduling
- coordination
If 32 workers execute DIFFERENT instructions: hardware pays those costs repeatedly.
If 32 workers execute the SAME instruction on different data: hardware fetches / decodes / schedules once, then broadcasts execution across all lanes.
This is amortization: sharing one overhead across massive amounts of work.
Put numbers on it. Let $t_f$, $t_d$, $t_e$ be the time for fetch, decode, execute, and let $W$ be the SIMT/SIMD width (e.g. $W = 32$ for a GPU warp). One vector instruction processes $W$ items in a single $(t_f + t_d + t_e)$ cycle. So for $N$ items (with $N$ a multiple of $W$ for simplicity):
$$ T_{\text{scalar}}(N) \;=\; N\,(t_f + t_d + t_e) \qquad\quad T_{\text{SIMT}}(N, W) \;=\; \frac{N}{W}\,(t_f + t_d + t_e) $$
The raw speedup is just the lane count:
$$ \text{Speedup} \;=\; \frac{T_{\text{scalar}}}{T_{\text{SIMT}}} \;=\; W $$
But the amortization is sharper when you look at the control cost per item:
$$ \underbrace{(t_f + t_d)}_{\text{scalar, per item}} \;\;\longrightarrow\;\; \underbrace{\frac{t_f + t_d}{W}}_{\text{SIMT, per item}} $$
Control overhead per useful op drops by a factor of $W$. With $W = 32$, that's a $32\times$ cheaper fetch+decode amortized across every item the warp touches and that is the throughput.
That's the heart of:
- SIMD
- SIMT
- tensor cores
- batching
- GPU throughput
Uniformity → amortized control cost → cheap parallelism
Diversity / irregularity → broken amortization → expensive coordination
This also explains:
- warp divergence
- why GPUs hate branches
- why branch-free kernels are fast
- why tensor cores want regular shapes
- why batching inference is powerful
Warp divergence has a clean cost formula. A warp of $W=32$ lanes that splits across $k$ distinct control-flow paths must execute each path serially, with most lanes idle on every pass. Effective utilization and runtime are
$$ \eta_{\text{warp}} \;=\; \frac{1}{k} \qquad\qquad T_{\text{warp}} \;=\; k \cdot T_{\text{path}} $$
So a 4-way branch turns one warp into a $4\times$ slowdown, not because the math got harder, but because the broadcast got broken.
Optimization is reducing dependency cost
Most advanced optimization is NOT "make arithmetic faster."
It is: "reduce dependency cost."
Examples:
- overlap compute + communication
- lock-free structures
- batching
- async execution
- CUDA streams
- speculative execution
- pipeline balancing
All try to reduce: waiting, synchronization, coordination overhead.
Everything compresses into five ideas
- Find independence
- Preserve uniformity
- Minimize coordination
- Amortize overhead
- Keep hardware busy
And suddenly: GPUs, CPUs, distributed systems, databases, networking, operating systems, they all start feeling like variations of the same deep ideas.
The mechanism: why uniformity → throughput
- The high-level claim is "uniform execution amortizes overhead."
Here's the mechanistic picture, what's actually happening at the gate level:
The mental model I keep coming back to:
- Find independence in your workload, then design execution so the hardware can amortize control across it.
- Everything else: kernels, schedulers, runtimes, communication layers, is plumbing in service of that.